协同过滤可以简单理解为人们对“人以群分,物以类聚”算法解释和应用 。
人以群分——基于用户的协同过滤
基于用户的协同过滤主要基于的是用户之间的相似度(依赖用户的历史喜好数据),先计算用户之间的相似度 , 然后将用户喜欢的物品推荐给相似用户 。也就是说,当用户需要个性化推荐时 , 可以先找到与他相似其他用户(通过兴趣、爱好或行为习惯等) , 然后把那些相似用户喜欢的并且自己不知道的物品推荐给用户 。
物以类聚——基于物品的协同过滤
基于项目(item-based)的协同过滤基于物品之间的相似度,先计算物品之间的相似度,然后根据用户对物品的评分,将用户喜欢物品的相似物品推荐给用户 。也就是说,当一个用户需要个性化推荐时,例如由于他之前购买过《集体智慧编程》这本书,所以会给他推荐《机器学习实战》,因为其他用户很多都同时购买了这两本书 。
基于用户协同过滤与基于物品协同过滤的区别
基于用户的协同过滤需要在线(系统上线后)找用户和用户之间的相似度关系 , 计算复杂度肯定会比基于物品的协同过滤高 。同时还需考虑推荐算法的冷启动问题(如何在没有大量用户数据的前提下能够让用户对推荐结果满意),比如可以通过用户注册时让用户选择自己感兴趣的领域,生成粗粒度的推荐 。
基于用户的协同过滤是给用户推荐那些和他有共同兴趣的用户喜欢的物品,所以基于用户的协同过滤推荐较为社会化,即推荐的物品是与用户兴趣一致的那个群体中的热门物品,同时能够推荐给用户新类别物品 。
基于物品协同过滤则是为用户推荐那些和他之前喜欢的物品类似的物品 , 基于物品协同过滤的推荐较为个性,因为推荐的物品一般都满足自己的独特兴趣 , 所以比较是适应于用户个性化需求强烈的领域,但由于物品的相似度比较稳定,很难推荐给用户新类别的物品 。
协同过滤是推荐系统中采用的一种技术手段,简单地说就是利用跟你有某些相似之处的群体的喜好行为来推荐你可能感的兴趣的信息 , 跟你行为相似的用户或者用户行为能帮助过滤筛选你想要的信息 , 达到一种“协同”的效果 。
举例来说,比如你现在想去看电影,但是不知道在众多的电影之中选择哪一部 , 这时你会怎么做?
【协同过滤为啥叫协同过滤 如何理解协同过滤】
你可能问你身边的朋友、同事、同学 , 他们最近看了什么好看电影,你会参考他们的选择 。
或者 , 打开视频网站,你在选择电影的时候,你会偏向去你之前经常看的电影类别中,找一找有没有什么新出的这类题材的电影,比如你之前是一个钢铁侠迷 , 钢铁侠系列的电影你都看过了 , 你可能就会再去看美国队长等 。
上面这个例子 , 就展现了协同过滤的思想及两种方式:基于用户的协同过滤和基于物品的协同过滤 。
1)基于用户的协同过滤,目标就是寻找跟你行为相似度高的用户,把他们的选择推荐给你 。如下图所示:
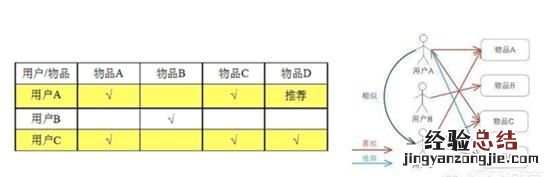
但这种方式,会面临一些问题,一是对于一个没有什么行为积累的新用户,很难找到跟他行为相似的用户;二是 , 本用户关系的某类产品 , 跟其相似的用户在该类产品的选择上很少,也无法推荐;三是,人是善变的动物,比如 , 你之前特别爱手游 , 某一天你突然把游戏戒掉了,那在给你推荐游戏类的软件就是无用的 。因此基于用户的协同过滤在实际应用中,因用户表稀疏,且不易维护往往不常使用 。
2)基于物品的协同过滤 , 既然用户不便维护,我们就寻求物品之间的相似度 。因为物品的一旦生产出来,特性就是确定的,而且商家为了能更好地卖出商品,也会积极描述物品的特点,因此基于物品的协同过滤,物品的特征更容易获取 , 也就更容易计算物品之间的相似度 。
而在实际中,也要根据不同的应用场景选择合适的方式,比如,如果做新闻推荐的话,就最好选择基于用户的方式 , 实时进行推荐 。如果是做电商、像图书、电影等,就更适合基于物品的推荐 。














