6.2 实际应用中的集群我们现在测试了两个Google正在使用的集群,它们有一定的代表性 。集群A通常用于上百个工程师进行研究和开发 。一个普通的任务被人为初始化,并运行几个小时,它读取几MB到几TB的数据,进行转换或分析数据,并将结果写回到集群中 。集群B主要用于生产数据的处理 。在很少人为干预下,这些任务运行更长的时间,持续的产生和处理几TB的数据集 。在这两个实例中,一个单独的任务由运行在很多机器上的很多进程同时读和写很多文件组成 。
6.2.1 存储
文章插图
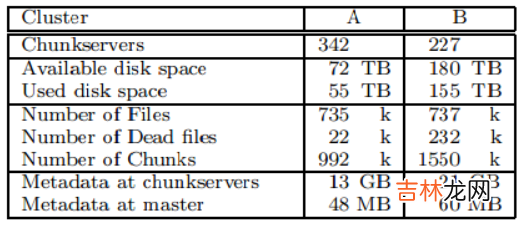
表2:两个GFS集群的属性
如表2的前五个条目所示,两个集群都有上百个块服务器,支持数TB的磁盘空间,存储了大小合适的数据,但没有占满 。“已使用空间”包括所有的块副本 。实际上,所有的文件都有三个副本,因此,集群实际上存储了18TB和52TB的文件数据 。
两个集群的文件数量相近,不过B含有更大比例的死文件,死文件是指被删除或者被新版本替换的文件,但它们的存储空间还没有被回收 。它也存储了更多的块,因为它的文件较大 。
6.2.2 元数据块服务器总共存储了数10GB的元数据,大多数是用户数据64KB的block的校验和 。块服务器上其它的元数据则是4.5节讨论的块版本号 。
Master上的元数据要小很多,只有几十MB,或者说,每个文件平均有100字节的元数据 。这符合我们对Master内存在实际中不会限制系统能力的设想 。大多数的文件元数据是以前缀压缩方式存放的文件名,其它的元数据包括文件的所有者和权限,文件到块的映射表,以及每个块的当前版本号 。此外,还为每个块存储了当前副本的位置信息和引用计数用来实现写时拷贝(COW) 。
每个单独的服务器,不论是块服务器还是Master,只有50-100MB的元数据 。因此恢复速度很快:在服务器能够应答请求之前,它会只花费几秒时间先从磁盘中读取元数据 。然而,主节点会持续颠簸一段时间,通常是30秒-60秒,直到它从所有的块服务器上获取到块位置信息 。
6.2.3 读写速率
文章插图
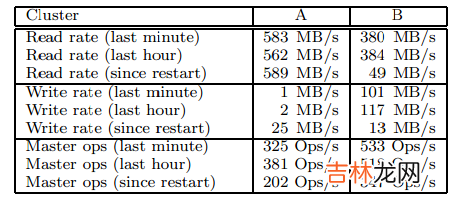
表3:两个GFS集群的性能度量
表3中显示了持续时间不同的读写速率,两个集群在做这些测试前都已经运行了大概一个星期的时间 。(这两个集群是因为GFS更新到新版本而进行重启 。)
自从重启后,平均写速率一直小于30MB/s 。当我们做这些测试时,B正在进行速率为100MB/s的大量写操作,因为写操作被传送到三个副本上,所以将产生300MB/s的网络负载 。
读速率要达到高于写速率 。如我们设想的那样,整个工作由更多的读操作组成 。两个集群都在进行繁重的读操作,特别是,集群A在前些周维持了580MB/s的读速率 。它的网络配置能够支持750MB/s的速率,所以它有效的利用了它的资源 。集群B支持的极限读速率为1300MB/s,但是,它的应用只用到了380MB/s 。
6.2.4 Master复制表3也显示了发往Master的操作速率,每秒有200-500个操作 。Master可以轻松的应对这个速率,因此Master的处理性能不是瓶颈 。
在早期的GFS版本中,Master有时会成为瓶颈 。它花费大多数时间连续的浏览大的目录(可能含有几百几千个文件)来查找指定的文件 。我们已经改变了Master的数据结构,使用二分查找在命名空间中进行查找,以此提高效率 。它也能轻松的支持每秒数千次的文件访问 。如果需要,我们能通过在命名空间数据结构之前放置名字查询缓存的方法来进一步提高速度 。
6.2.5 恢
经验总结扩展阅读













- google发送的通知在哪 谷歌发送的通知在哪里找
- JAVA的File对象
- Codeforces 1670 E. Hemose on the Tree
- 二 沁恒CH32V003: Ubuntu20.04 MRS和Makefile开发环境配置
- 驱动开发:内核监控FileObject文件回调
- 伤感英文句子带翻译 英文扎心短句大全
- 齐博X1-栏目的调用2
- Blazor组件自做十一 : File System Access 文件系统访问 组件
- How to get the return value of the setTimeout inner function in js All In One
- System.IO.FileSystemWatcher的坑