6. 度量在这章中,我们介绍几个微基准测试来描述 GFS 架构和实现中固有的瓶颈,还有一些来自于 Google 正在使用的集群中 。
6.1 微基准测试我们在一个由1个主节点,2个主节点副本,16个块服务器和16个客户端组成的GFS系统上进行性能测试 。注意,这个配置是为了方便测试,一般的集群包含数百个块服务器和数百个客户端 。
所有的机器都配置为两个1.4GHz的PIII处理器,2GB的内存,两个5400rpm的80GB的磁盘,以及一个100Mpbs全双工以太网连接到一个HP2524的交换机上 。两个交换机之间只用1Gpbs的链路连接 。
6.1.1 读操作N个客户端同时从文件系统读取数据 。每个客户端从320GB的数据中,随机的选取4MB区间进行读取 。这个读操作会重复256次,使客户端最终读取到1GB的数据 。块服务器总共只有32GB的内存,,所以我们期望最多有10%的缓存命中率 。我们的结果应该与没有缓存的情况下相近 。
文章插图
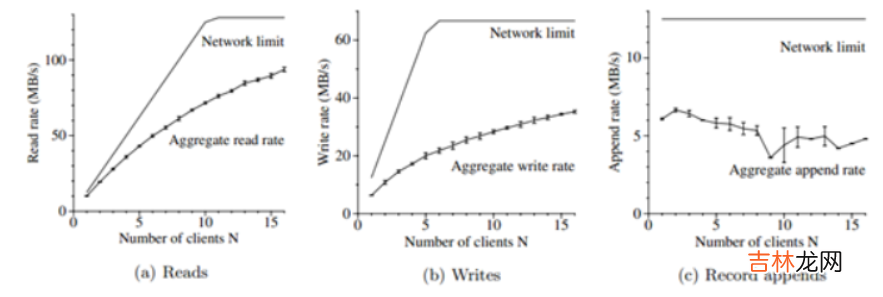
图3:总吞吐量 。顶上的曲线显示了理论情况下的由我们的网络拓扑引入的限制 。下面的曲线显示了测试的吞吐量 。它们显示了置信区间为95%的误差,在一些情况下,由于测量的方差小而不太明显 。
【The Google File System 翻译和理解】图3(a)中显示了N个客户端的总读取速率和它的理论极限 。当两个交换机之间的1Gpbs链路饱和时,理论极限为125MB/s,或者当客户端的网络接口达到饱和时,每个客户端的理论极限为12.5MB/s,无论哪个都适用 。当只有一个客户端进行读取时,观测到的读取速率为10MB/s,或者是每个客户端极限的80% 。对于16个读操作,总速率可以达到94MB/s,大约是125MB/s网络极限的75%,或者是每个客户端到达6MB/s的速率 。效率从80%下降到75%的原因是,当读取操作的数量增加时,多个读操可能同时的从同一个块服务器上读取数据 。
6.1.2 写操作N个客户端同时往N个不同文件进行写操作 。每个客户端以每次1MB的速率向一个新文件写入1GB的数据 。总的写入速率和理论极限显示在图3(b)中 。理论极限是67MB/s,因为我们需要把每个字节都写入到16个块服务器中的3个,而每个块服务器的输入连接极限为12.5MB/s 。
每个客户端的写入速率为6.3MB/s,大约是极限的一半,主要的原因是我们的网络协议栈,它与我们用于推送块副本的管道(pipelining)方式不太适应 。从一个副本到另一个副本传播数据的延迟降低了整个系统的写入速率 。
16个客户端的总写入速率达到35MB/s(每个客户端的速率大概是2.2MB/s),大约是理论极限的一半 。与多个客户端进行读操作的情况类似,由于进行写操作的客户端数量的增加,客户端同时向同一个块服务器写入的几率也会增加 。此外,写操作冲突的几率比读操作的要更大,因为每次写操作需要涉及三个不同的副本 。
写操作比我们想要的要慢,在实际中,这不会成为一个主要的问题,因为即使对于单个客户端它也增加了时延,但是对于含有大量客户端的系统来说,它不会对系统的写入带宽有太大影响 。
6.1.3 记录追加图3(c)显示了记录追加的性能,N个客户端同时向一个单独的文件追加数据 。性能受存储文件最后一个块的块服务器的网络带宽的限制,而不是客户端的数量 。它的速率由一个客户端的6MB/s下降到16个客户端的4.8MB/s,主要是由冲突和不同客户端的网络传输速率不同造成的 。
我们的应用倾向于同时处理多个这样的文件 。换句话说,N个客户端同时向M个共享文件追加数据,N和M在0到几百之间 。因此,在我们的经验中,块服务器网络冲突在实际中不是一个严重的问题,因为当块服务器正在忙于处理一个文件时,客户端可以进行另一个文件的写入操作 。
经验总结扩展阅读











- google发送的通知在哪 谷歌发送的通知在哪里找
- JAVA的File对象
- Codeforces 1670 E. Hemose on the Tree
- 二 沁恒CH32V003: Ubuntu20.04 MRS和Makefile开发环境配置
- 驱动开发:内核监控FileObject文件回调
- 伤感英文句子带翻译 英文扎心短句大全
- 齐博X1-栏目的调用2
- Blazor组件自做十一 : File System Access 文件系统访问 组件
- How to get the return value of the setTimeout inner function in js All In One
- System.IO.FileSystemWatcher的坑