也就是说这不是真正意义上的非阻塞IO 。
IO 多路复用
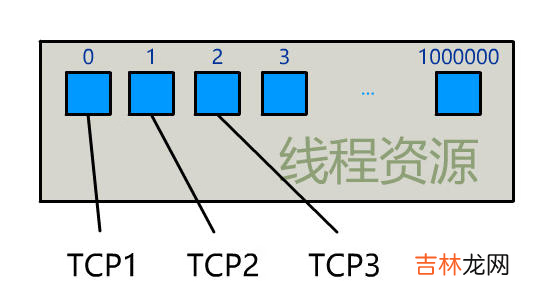
为每个客户端创建一个线程,服务器端的线程资源很容易被耗光 。
文章插图
当然还有个聪明的办法,我们可以每 accept 一个客户端连接后,将这个文件描述符(connfd)放到一个数组里 。
fdlist.add(connfd);然后弄一个新的线程去不断遍历这个数组,调用每一个元素的非阻塞 read 方法 。- while(1) {
- for(fd <-- fdlist) {
- if(read(fd) != -1) {
- doSomeThing();
- }
- }
- }

文章插图
你是不是觉得这有些多路复用的意思?
但这和我们用多线程去将阻塞 IO 改造成看起来是非阻塞 IO 一样,这种遍历方式也只是我们用户自己想出的小把戏,每次遍历遇到 read 返回 -1 时仍然是一次浪费资源的系统调用 。
所以,还是得恳请操作系统老大,提供给我们一个有这样效果的函数,我们将一批文件描述符通过一次系统调用传给内核,由内核层去遍历(而不是在用户态调用,再陷入到内核态中去遍历),才能真正解决这个问题 。
selectselect 是操作系统提供的系统调用函数,通过它,我们可以把一个文件描述符的数组发给操作系统,让操作系统去遍历,确定哪个文件描述符可以读写,然后告诉我们去处理:

文章插图
select系统调用的函数定义如下 。
- int select(
- int nfds,
- fd_set *readfds,
- fd_set *writefds,
- fd_set *exceptfds,
- struct timeval *timeout);
- // nfds:监控的文件描述符集里最大文件描述符加1
- // readfds:监控有读数据到达文件描述符集合,传入传出参数
- // writefds:监控写数据到达文件描述符集合,传入传出参数
- // exceptfds:监控异常发生达文件描述符集合, 传入传出参数
- // timeout:定时阻塞监控时间,3种情况
- //1.NULL,永远等下去
- //2.设置timeval,等待固定时间
- //3.设置timeval里时间均为0,检查描述字后立即返回,轮询
首先一个线程不断接受客户端连接,并把 socket 文件描述符放到一个 list 里 。
- while(1) {
- connfd = accept(listenfd);
- fcntl(connfd, F_SETFL, O_NONBLOCK);
- fdlist.add(connfd);
- }
- while(1) {
- // 把一堆文件描述符 list 传给 select 函数
- // 有已就绪的文件描述符就返回,nready 表示有多少个就绪的
- nready = select(list);
- ...
- }
只不过,操作系统会将准备就绪的文件描述符做上标识,用户层将不会再有无意义的系统调用开销 。
- while(1) {
- nready = select(list);
- // 用户层依然要遍历,只不过少了很多无效的系统调用
- for(fd <-- fdlist) {
- if(fd != -1) {
- // 只读已就绪的文件描述符
- read(fd, buf);
- // 总共只有 nready 个已就绪描述符,不用过多遍历
- if(--nready == 0) break;
- }
- }
- }
经验总结扩展阅读










- iPhone8怎么刷机(苹果x强制恢复出厂)
- soul怎么找回之前聊天的人 soul恢复聊天列表方法
- 超人怎么死的(超人怎么复活)
- 廉租房一般几室一厅 廉租房享用的国家政策有哪些
- 一般蛋糕店用的是什么奶油
- 记一次多个Java Agent同时使用的类增强冲突问题及分析
- 光遇啵啵先祖裤子怎么搭配
- fastposter v2.10.0 简单易用的海报生成器
- 螺蛳粉要泡多久
- 羊毛衫缩水了有什么办法可以恢复