起初我们考虑在主节点永久地保存块位置信息,但后来发现在启动时向块服务器请求数据并在此后进行周期性更新要简单许多 。这消除了当块服务器加入或离开集群、更改名字、出错、重启等异常发生时,保持主节点和块服务器同步的问题 。在大型集群中这些问题发生得很频繁 。
理解这种设计的另一个角度是:认识到块服务器对他的磁盘上最终存储或不存储某个块有最终的决定权 。在主节点上维护这些信息的一致性视图是没有意义的,因为块服务器上的错误可能会导致块发生主服务器不能及时知悉的变动,例如块被删除或重命名等 。
2.6.3 操作日志操作日志包含了关键的元数据变化的历史记录,是 GFS 的核心 。它不仅永久的记录了元数据,还能提供确定并发操作顺序的逻辑时间线服务 。文件和块,连同它们的版本,都是由它们创建的逻辑时间唯一的、永久的进行标识的 。
因为操作日志是临界资源,我们必须可靠的存储它,在元数据的变化持久化之前,客户端是无法看到这些操作日志的 。否则,即使块本身保存下来,仍然有可能丢失整个文件系统或者客户端最近的操作 。因此,我们将它复制到几个远程的机器上,并在将相应的操作刷新(flush)到本地和远程磁盘后再回复客户端 。主节点会在刷新之前批处理一些日志记录,以此减少刷新和系统内复制对整个系统吞吐量的影响 。
主节点通过重新执行操作日志来恢复状态 。为了使启动时间尽量短,我们必须保持日志较小 。当日志超过一个特定的大小时,主节点会检查它的状态 。这样一来,以使它能够在足够小的代价下通过载入本地磁盘的最后一个检查点及之后的日志记录进行恢复 。检查点是一个类似 B 树的数据结构,能够直接映射到内存中,并且在用于命名空间查询时无需额外的解析 。这大大提高了恢复速度,增加了可用性 。
因为创建检查点需要一定的时间,所以主节点的内部状态会被格式化,格式化的结果保证了新检查点的创建不会阻塞正在进行的修改操作 。当主节点切换到新的日志文件时,GFS 通过另一个线程进行新检查点的创建 。新检查点包括切换前所有的修改操作 。对于一个有几百万文件的集群来说,创建一个新检查点大概需要1分钟 。当创建完成后,它将写入本地和远程磁盘 。
恢复只需要最近完成的检查点和在此之后的日志文件 。老的检查点和日志文件能够被删除,但为了应对灾难性故障,我们会保留其中的一部分 。检查点的失败不会影响恢复的正确性,因为恢复代码会探测并跳过未完成的检查点 。
2.7 一致性模型GFS 采用弱一致性模型,能很好的支持分布式应用,同时实现上比较简单 。我们在这里将讨论 GFS 的一致性保障机制以及其对于应用的意义 。我们也将着重描述了 GFS 如何维持这些一致性保障机制,但将一些细节留在了其它章节 。
2.7.1 GFS的一致性保障机制文件命名空间修改(如,创建文件)是原子性的 。它们仅由主节点进行处理:命名空间锁保障了操作的原子性和正确性;主节点操作日志定义了这些操作的全局排序 。
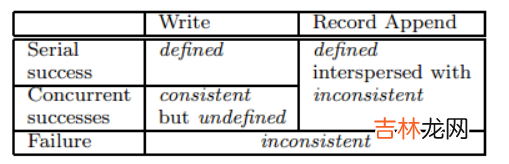
下图是经过修改后的文件区域状态表:
文章插图
一个文件区域(region)在一个数据修改后的状态依赖于该修改的类型、成功或失败、以及是否为同步的修改 。表1 总结了一次修改后的结果 。
- 如果所有的客户端无论从哪些副本读取数据,得到的数据都是相同的,则这个文件区域为一致的 consistent 。
- 在一个文件数据修改后,如果它是一致的,则这个区域已定义 defined,客户端将看到被写入的全部内容 。
经验总结扩展阅读
- google发送的通知在哪 谷歌发送的通知在哪里找
- JAVA的File对象
- Codeforces 1670 E. Hemose on the Tree
- 二 沁恒CH32V003: Ubuntu20.04 MRS和Makefile开发环境配置
- 驱动开发:内核监控FileObject文件回调
- 伤感英文句子带翻译 英文扎心短句大全
- 齐博X1-栏目的调用2
- Blazor组件自做十一 : File System Access 文件系统访问 组件
- How to get the return value of the setTimeout inner function in js All In One
- System.IO.FileSystemWatcher的坑