SqlFieldsQuery sql = new SqlFieldsQuery("select name from City").setSchema("PERSON");或者,您可以在语句中定义架构:
SqlFieldsQuery sql = new SqlFieldsQuery("select name from Person.City");8.创建表您可以将任何受支持的 DDL 语句传递到SqlFieldsQuery缓存并在缓存上执行,如下所示 。
IgniteCache<Long, Person> cache = ignite.getOrCreateCache(new CacheConfiguration<Long, Person>().setName("Person"));// Creating City table.cache.query(new SqlFieldsQuery("CREATE TABLE City (id int primary key, name varchar, region varchar)")).getAll();在 SQL 模式方面,执行代码会创建以下表:
- “Person”模式中的表“Person”(如果之前没有创建过) 。
- “人员”模式中的表“城市” 。
9.取消查询有两种方法可以取消长时间运行的查询 。
第一种方法是通过设置查询执行超时来防止查询失控 。
SqlFieldsQuery query = new SqlFieldsQuery("SELECT * from Person");// Setting query execution timeoutquery.setTimeout(10_000, TimeUnit.SECONDS);第二种方法是通过使用来停止查询QueryCursor.close() 。
SqlFieldsQuery query = new SqlFieldsQuery("SELECT * FROM Person");// Executing the queryQueryCursor<List<?>> cursor = cache.query(query);// Halting the query that might be still in progress.cursor.close();2.6.6 机器学习Apache Ignite 机器学习 (ML) 是一组简单、可扩展且高效的工具,无需昂贵的数据传输即可构建预测机器学习模型 。
将机器和深度学习 (DL) 添加到 Apache Ignite 的基本原理非常简单 。今天的数据科学家必须处理阻碍 ML 被主流采用的两个主要因素:
- 首先,在不同的系统中训练和部署模型(训练结束后) 。数据科学家必须等待 ETL 或其他一些数据传输过程才能将数据移动到 Apache Mahout 或 Apache Spark 等系统中以进行培训 。然后他们必须等待此过程完成并在生产环境中重新部署模型 。整个过程可能需要数小时才能将数 TB 的数据从一个系统转移到另一个系统 。此外,训练部分通常发生在旧数据集上 。
- 第二个因素与可扩展性有关 。必须处理不再适合单个服务器单元的数据集的 ML 和 DL 算法正在不断增长 。这促使数据科学家提出复杂的解决方案,或者转向分布式计算平台,如 Apache Spark 和 TensorFlow 。然而,这些平台大多只解决了模型训练的一部分难题,这使得开发人员决定以后如何在生产中部署模型成为负担 。
文章插图
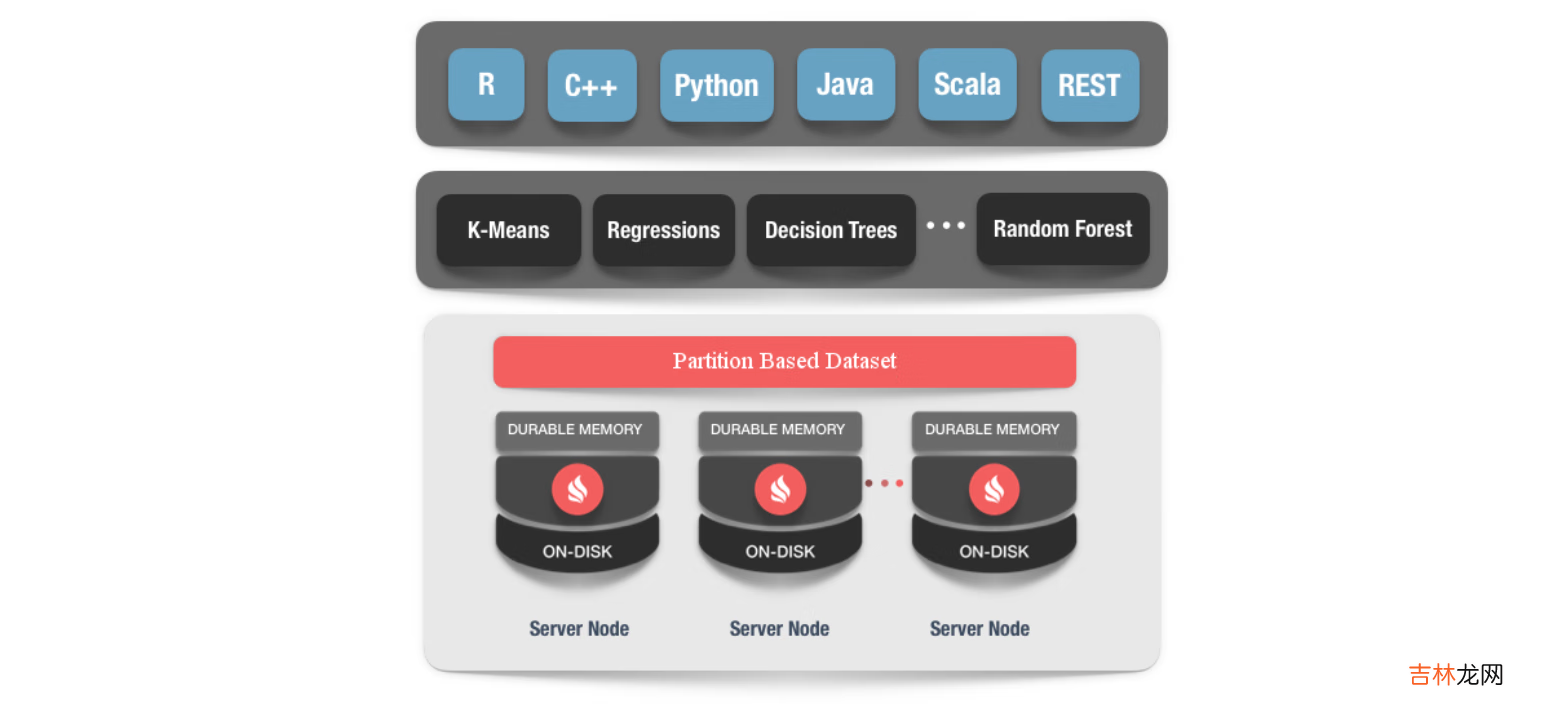
1.零 ETL 和大规模可扩展性Ignite 机器学习依赖于 Ignite 以内存为中心的存储,它为 ML 和 DL 任务带来了巨大的可扩展性,并消除了 ETL 在不同系统之间施加的等待 。例如,它允许用户直接在 Ignite 集群中跨内存和磁盘存储的数据上运行 ML/DL 训练和推理 。接下来,Ignite 提供了大量针对 Ignite 的并置分布式处理进行优化的 ML 和 DL 算法 。当针对大量数据集或增量针对传入数据流运行时,这些实现提供内存速度和无限的水平可扩展性,而无需将数据移动到另一个存储中 。通过消除数据移动和较长的处理等待时间
2.容错和持续学习Apache Ignite 机器学习可以容忍节点故障 。这意味着在学习过程中出现节点故障的情况下,所有的恢复过程对用户都是透明的,学习过程不会中断,我们会在类似于所有节点都正常工作的情况下得到结果 。
3.算法和适用性3.1 分类根据训练集识别新观察属于哪个类别 。
- 适用性:垃圾邮件检测、图像识别、信用评分、疾病识别 。
经验总结扩展阅读
- 快读《ASP.NET Core技术内幕与项目实战》WebApi3.1:WebApi最佳实践
- IQueryable和IEnumerable 快读《ASP.NET Core技术内幕与项目实战》EFCore2.5:集合查询原理揭秘
- Spring事务传播行为实战
- 四十八 SpringCloud微服务实战——搭建企业级开发框架:【移动开发】整合uni-app搭建移动端快速开发框架-使用第三方UI框架
- React +SpreadJS+Echarts 项目实战:在线报价采购系统
- 四十七 SpringCloud微服务实战——搭建企业级开发框架:【移动开发】整合uni-app搭建移动端快速开发框架-添加Axios并实现登录功能
- 【一】ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?
- Module XAF新手入门 - 模块
- 3 Python全栈工程师之从网页搭建入门到Flask全栈项目实战 - 入门Flask微框架
- 机器学习实战-AdaBoost