文章插图
from sklearn.feature_extraction.text import TfidfTransformerimport datetimestarttime = datetime.datetime.now()transformer = TfidfTransformer()tfidf = transformer.fit_transform(X)word = vectorizer.get_feature_names()weight = tfidf.toarray()print(weight)
文章插图
词语分类:人工vsKmeans
from sklearn.cluster import KMeansstarttime = datetime.datetime.now()path = '训练集分词结果(随机选取1000个样本).xlsx'df = pd.read_excel(path,dtype=str)corpus = df['分词']kmeans=KMeans(n_clusters=10)#n_clusters:number of clusterkmeans.fit(weight)res = [list(df['类别']),list(kmeans.labels_)]df_res = pd.DataFrame(np.array(res).T,columns=['人工分类','Kmeans分类'])path_res = 'Kmeans自动分类结果.xlsx'df_res.to_excel(path_res,index=False)df_res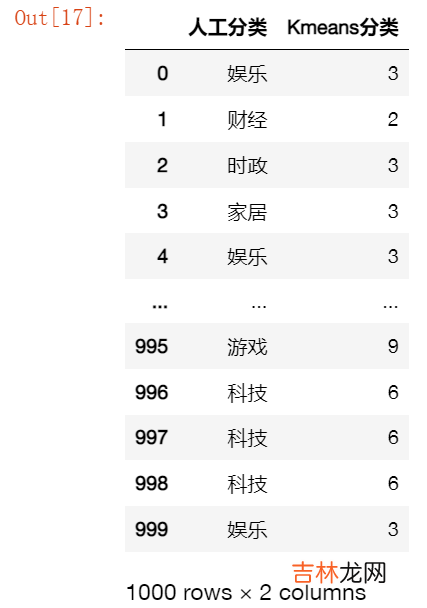
文章插图
path = 'Kmeans自动分类结果.xlsx'df = pd.read_excel(path,dtype=str)df['计数'] = [1 for m in range(len(df['人工分类']))]df1 = pd.pivot_table(df, index=['人工分类'], columns=['Kmeans分类'], values=['计数'], aggfunc=np.sum, fill_value=https://www.huyubaike.com/biancheng/0)co = ['人工分类']co.extend(list(df1['计数'].columns))df1 = df1.reset_index()df2 = pd.DataFrame((np.array(df1)),columns=co)path_res = '人工与Kmeans分类结果对照.xlsx'df2.to_excel(path_res,index=False)df2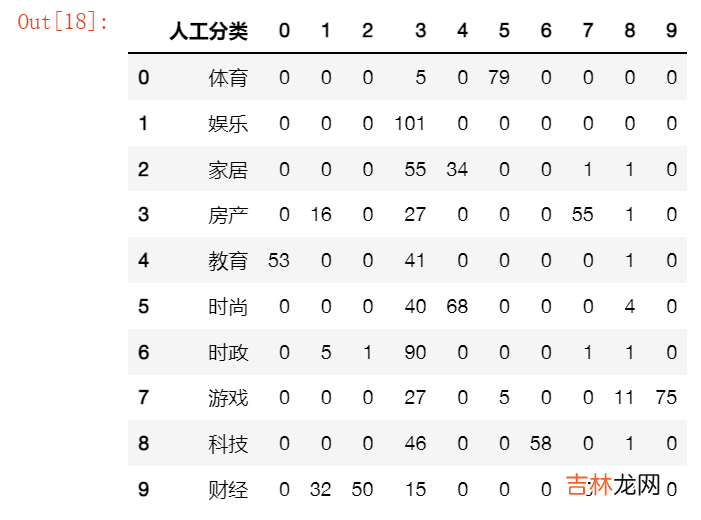
文章插图
import randomdef is_contain_chinese(check_str):for ch in check_str:if u'\u4e00' <= ch <= u'\u9fff':return 1return 0def generatorInfo(file_name):"""batch_size:生成数据的batch sizeseq_length:输入文字序列长度num_classes:文本的类别数file_name:读取文件的路径"""# 读取文本文件with open(file_name, encoding='utf-8') as file:line_list = [k.strip() for k in file.readlines()]#data_label_list = []# 创建数据标签文件#data_content_list = []# 创建数据文本文件data = https://www.huyubaike.com/biancheng/[]for k in random.sample(line_list,1000):t = k.split(maxsplit=1)#data_label_list.append(t[0])#data_content_list.append(t[1])data.append([t[0],' '.join([w for w,flag in jieba.posseg.cut(t[1]) if (w not in dfs['stopwords']) and (w !=' ') and (flag not in ["nr","ns","nt","nz","m","f","ul","l","r","t"]) and (len(w)>=2)])])return data#导入中文停用词表paths = '中英文停用词.xlsx'dfs = pd.read_excel(paths,dtype=str)file_name = 'cnews.train.txt'df = pd.DataFrame(np.array(generatorInfo(file_name)),columns=['类别','分词'])df
文章插图
汇总
import randomimport jiebaimport pandas as pdimport numpy as npfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.cluster import KMeansfrom sklearn.feature_extraction.text import TfidfTransformerdef is_contain_chinese(check_str):for ch in check_str:if u'\u4e00' <= ch <= u'\u9fff':return 1return 0def generatorInfo(file_name):"""batch_size:生成数据的batch sizeseq_length:输入文字序列长度num_classes:文本的类别数file_name:读取文件的路径"""# 读取文本文件with open(file_name, encoding='utf-8') as file:line_list = [k.strip() for k in file.readlines()]#data_label_list = []# 创建数据标签文件#data_content_list = []# 创建数据文本文件data = https://www.huyubaike.com/biancheng/[]for k in random.sample(line_list,1000):t = k.split(maxsplit=1)#data_label_list.append(t[0])#data_content_list.append(t[1])data.append([t[0],' '.join([w for w,flag in jieba.posseg.cut(t[1]) if (w not in dfs['stopwords']) and (w !=' ') and (flag not in ["nr","ns","nt","nz","m","f","ul","l","r","t"]) and (len(w)>=2)])])return data#导入中文停用词表paths = '中英文停用词.xlsx'dfs = pd.read_excel(paths,dtype=str)file_name = 'cnews.train.txt'df = pd.DataFrame(np.array(generatorInfo(file_name)),columns=['类别','分词'])#统计词频corpus = df['分词'] #语料中的单词以空格隔开#vectorizer = CountVectorizer(max_features=5000)vectorizer = CountVectorizer()X = vectorizer.fit_transform(corpus)#文本向量化transformer = TfidfTransformer()tfidf = transformer.fit_transform(X)word = vectorizer.get_feature_names()weight = tfidf.toarray()kmeans=KMeans(n_clusters=10)#n_clusters:number of clusterkmeans.fit(weight)res = [list(df['类别']),list(kmeans.labels_)]df_res = pd.DataFrame(np.array(res).T,columns=['人工分类','Kmeans分类'])df_res['计数'] = [1 for m in range(len(df_res['人工分类']))]df1 = pd.pivot_table(df_res, index=['人工分类'], columns=['Kmeans分类'], values=['计数'], aggfunc=np.sum, fill_value=https://www.huyubaike.com/biancheng/0)co = ['人工分类']co.extend(list(df1['计数'].columns))df1 = df1.reset_index()df2 = pd.DataFrame((np.array(df1)),columns=co)df2
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 抹茶粉怎么冲来喝
- 2023年9月26日挖掘池塘好不好 2023年农历八月十二挖掘池塘吉日
- 患难与共,对男人不离不弃的星座女
- 《上传那些事儿之Nest与Koa》——文件格式怎么了!
- 创造与魔法9月16日最新礼包兑换码是什么
- 婆媳最火文案短句 与婆媳相处的无奈的感悟
- 与婆媳相处的无奈的感悟 人生感悟婆媳关系的句子
- 光与夜之恋晴空漫野谈活动怎么玩
- 签名很与众不同经典有意义 成熟又内涵的签名
- 2023大数据与会计就业方向及前景









