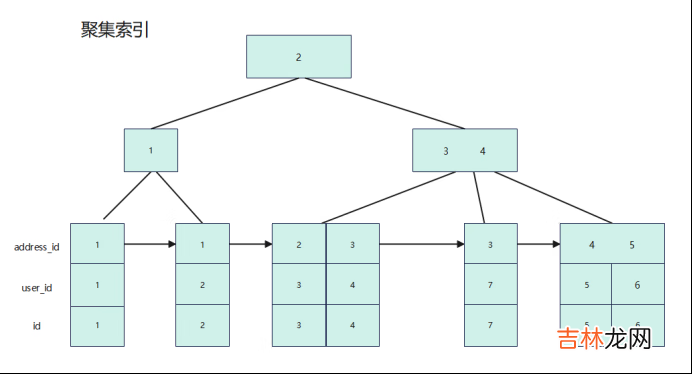
文章插图
文章插图
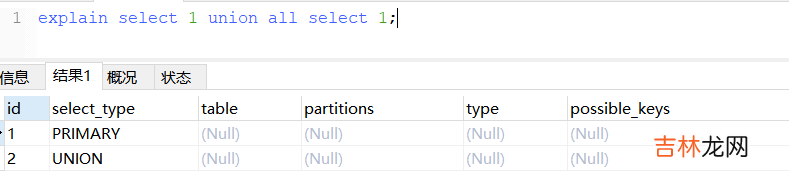
二、Explain中的列1、id列id列的编号是select的序列号,有几个select就有几个id,并且id的顺序是按select出现的顺序增长的 。
id列越大执行优先级越高,id相同则从上向下执行,id为null最后执行 。
2、select_type列2.1、Simple:简单查询,查询不包含子查询和union
EXPLAIN SELECT * from `user` WHERE id = 1;

文章插图
2.2、Primary:复杂查询中最外层的select
2.3、Subquery:包含在select中的子查询(不在from子句中)
2.4、Derived:包含在from子句中的子查询 。Mysql会将结果存放到一个临时表中,也成为派生表(derived的英文含义)
EXPLAIN SELECT (SELECT 1 FROM `user` WHERE id = 1) FROM (SELECT * FROM address WHERE id =1) der;

文章插图
注意:这里要先关闭一下mysql5.7新特性对衍生表的合并优化
set session optimizer_switch='derived_merge=off';
文章插图
3、Table对应正在访问的哪一个表,显示的是表明或者是别命,可能是临时表或者union合并结果集如果是具体的表名,则表明从实际的物理表中获取数据,当然也可以是表的别命
表明是derived的形式,表明使用了id为N的查询产生的衍生表,如下图所示:

文章插图
derived后面的id号为3,表明使用id为3的这个查询产生的衍生表,也就是(SELECT * FROM address WHERE id =1)这个查询语句结果集所在的的临时表
当有union result的时候,表名是union n1,n2等形式,n1,n2表示参与union的id
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着在访问表或索引 。例如:在索引列中取最小值,可以单独查找索引来完成,不需要在执行时访问表

文章插图
上面的语句我们是通过主键id的方式来查找的,如果看过我们上一篇博客的读者就能够明白,此时直接查索引就可以了,找到最小的,无需查表 。
4、possible_keys显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用
5、key实际使用的索引,如果为null,则没有使用索引,查询中若使用了覆盖索引,则该索引和查询的select字段重叠 。
如果没有使用索引,则该列是null,如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用force index、ignore index 。
基于4、5两个,有可能出现这种情况:possible_keys有值,key没有值,这种情况下有可能是因为分析的时候需要用索引,真正执行的时候发现不走索引的化还会快一点 。
6、Type这一列b表示关联类型或者访问类型,即Mysql决定如何查找表中的行,查找数据行记录的大概范围 。
依次从最优到最差分别为:
system>const>eq_ref>ref>range>index>ALL
一般来说,的保证查询达到range级别,最好达到ref 。
1)NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着在访问表或索引 。例如:在索引列中取最小值,可以单独查找索引来完成,不需要在执行时访问表

文章插图
2)system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现
经验总结扩展阅读











- 迷你世界10月19日激活码是多少
- 幼儿园国庆节放假通知及温馨提示
- 头伏吃什么二伏吃什么三伏吃什么
- SpringBoot+Vue3 AgileBoot - 手把手一步一步带你Run起全栈项目
- 能够满足你一切少女心的星座男
- 越容易追到你就越容易抛弃你的星座
- 运动 减肥的尽头,其实是提高代谢,10个方法让你从125瘦到95斤
- 怎么p图(手机怎么p图改数字)
- 怎么判断自己是不是恋爱脑 这8种表现有你吗
- 短而精的个性签名有内涵 你一定会喜欢的签名